Kui kõik vajalikud andmed oleksid õigel ajal käes ja kvaliteetsed, oleks riikliku statistika tegemine puhas rõõm. Tegelikkuses on andmekogumine statistika tegemise protsessi kõige vaevalisem ja kallim osa. Sellepärast peab alati hoolikalt kaaluma, milliseid andmeid on vaja ja kuidas neid koguda.
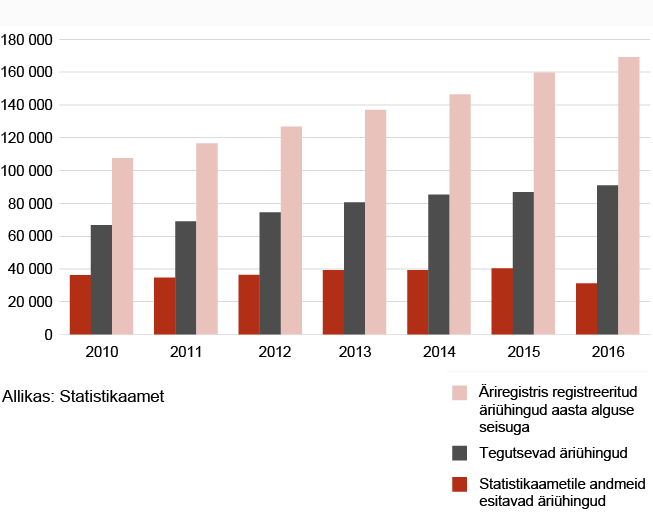
Majandus ja ettevõtlusstatistika tegemiseks peab ja uuendab Statistikaamet igal aastal majanduslikult aktiivsete majandusüksuste registrit, mida nimetatakse statistiliseks profiiliks. 2016. aastal on statistilises profiilis 152 000 majanduslikult aktiivset üksust. Koguda andmeid kõigilt üksustelt kõikide perioodide kohta on võimatu. Sellepärast kasutab Statistikaamet statistika tegemiseks valikuuringuid – väiksemate üksuste hulgast võetakse valdkondade kaupa juhuslikud valimid ja nendelt kogutud andmete põhjal hinnatakse huvipakkuva sihtgrupi kohta käivaid näitajaid. Teine tähtis põhjus valikuuringu kasutamiseks on majandusüksuste vastamiskoormuse vähendamine. On võimalik tekitada olukorda, kus erinevate uuringute valimid ei kattu või kattuvad väga vähe, mistõttu vastamiskoormus jaguneb üksuste vahel enam-vähem ühtlaselt.
Valikuuringu ideed rakendati esimest korda 19. ja 20. sajandi vahetusel Norras isikustatistikas. Nagu nimigi ütleb, kogutakse valikuuringu käigus andmeid vaid ainult ühelt osalt (valimilt) mitte kõigilt huvipakkuvatelt objektidelt (üldkogumilt). Esialgu võib tunduda, et valikuuringuga saame teada ainult seda, mis iseloomustab valimi objekte ja valimist väljajäänute kohta ei ole võimalik midagi öelda. Tegelikult sõltub kõik valimi koostamisest ehk võtmisest ja vähemal määral ka valimi suurusest, mida ja kui palju on võimalik valimi põhjal üldkogumi kohta teada saada.
Valimi võtmise viisi järgi jagunevad valimid kaheks
Kui võetakse valim, mis peab teatud tunnuste, näiteks vanuse ja soo, osas olema võimalikult üldkogumi sarnane ehk esindav, siis on tegemist empiirilise valimiga. Üldjuhul ei ole valimi sarnasust üldkogumiga uuritavate tunnuste osas võimalik mõõta, niisamuti ei ole võimalik näidata, milline valim on kindlalt uuritavate tunnuste osas esindav ja milline mitte. Empiirilise metoodika puhul on panus tehtud uurijate (ekspertide) kogemusele, mille järgi võetakse valimisse õigetes proportsioonides näiteks noori, vanu, rikkamaid, vaesemaid, erineva emakeelega, linna- ja maarahvast jne.
Teise valimite klassi moodustavad tõenäosuslikud valimid, mille võtmise alus on klassikaline tõenäosusteooria. Valimi võtmine jäetakse puhtalt juhuse hooleks ja mängitakse tõepoolest hasartmängu, st korraldatakse üldkogumi objektide vahel loterii või kasutatakse mõnda muud juhuslikku protseduuri. Tõenäosuslike valimite puhul pole mõtet rääkida valimi esindavusest – juhus on ükskõikne ja erapooletu. Tõenäosus, et isikute valimisse satuvad põhiliselt üksikud mehed või põhiharidusega naised vms, on kaduvväike. Vastupidi, juhus tõmbab valimisse objekte ka nähtamatute omaduste järgi õige osatähtsusega, näiteks erineva maailmavaate ja/või tervisliku seisundiga inimesi, ekstraverte ja introverte, blonde ja brünette jne. Tõenäosusliku valimi võtmiseks on vaja üldkogumisse kuuluvate objektide täielikku nimekirja.
Miks on tõenäosuslik valim hea?
Etteruttavalt – tõenäosusliku valimi puhul saab hinnata tulemuste kvaliteeti. Mängigu näidisüldkogumit 70 legoklotsi, mille kinnitusnuppude koguarv on 352.

Korraldame nende klotside vahel loterii: võtame välja 14 klotsi, juba väljavõetuid vahepeal tagasi ei pane. Sel viisil oleme võtnud tõenäosusliku valimi, mida nimetatakse lihtsaks juhuvalimiks.

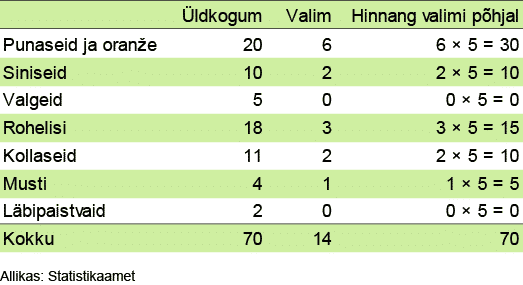
Kõigepealt paneme tähele, et valimisse on sattunud eri värvi klotse nagu on neid ka üldkogumis. Niisamuti on sarnaselt üldkogumiga tõmmatud valimisse väiksemaid ja suuremaid klotse. Seega tundub, et valim sarnaneb üldkogumile ja teisiti see ei saa ollagi, sest ausa loterii puhul on kõigil klotsidel võrdne võimalus välja tõmmatud saada. Veel enam, tõenäosuslikus valimis esindab iga objekt (klots) teatud hulka temaga sarnaseid objekte üldkogumis.
Et valimisse on võetud iga viies, siis eeldatakse, et üldkogumis leidub valimi iga klotsiga identseid klotse veel neli, st kokku viis ehk valimi iga klots esindab peale iseenda veel nelja. Identsuse eeldus on muidugi vale, kuid mitte täiesti. Vaadeldavasse valimisse on sattunud kuus punast ja oranži klotsi, seega üldkogumis peaks selliseid olema täpselt viis korda rohkem, st 6 x 5 = 30, tegelikult aga on seal selliseid klotse 20. Siniseid sattus valimisse kaks, järelikult üldkogumis peaks neid olema 2 x 5 = 10, mis juhtumisi peabki paika jne. Arvud 30 ja 10 on üldkogumi punaste/oranžide ja siniste klotside arvu vastavad hinnangud.
Analoogiliselt saab hinnata mistahes muid parameetreid, näiteks kinnitusnuppude kogusummat. Üldkogumis on see 352, valimis 76 ja üldkogumi kinnitusnuppude kogusumma hinnang on 76 x 5 = 380. Valimi osalisusest ja juhuslikkusest tingitud viga – valikuviga, on tõelise kogusumma ja selle hinnangu vahe 380 – 352 = 28. Käesoleval juhul moodustab valikuviga 7,4% tegelikust väärtusest. Päriselus ei ole valikuviga täpselt välja arvutada võimalik, sest kui üldkogumi kogusumma oleks teada, poleks ju vajadust seda hinnata. Tõenäosusliku valikuuringu puhul on aga võimalik valikuviga hinnata näidates vahemiku, kuhu tegelik kogusumma teatud tõenäosusega kuulub. Seda vahemikku nimetatakse usaldusvahemikuks. Usaldusvahemiku laius sõltub statistikatarbija riskitaluvusest ja arvutatakse nn standardvea alusel. Koormamata lugejat eelduste, üksikasjade ja valemitega võib antud valimi põhjal eeldada, et vahemik 311 kuni 448 katab tegeliku kogusumma tõenäosusega 0,95 ja nii see tõepoolest on.
Juhusliku valimi kasutamine ettevõtlusstatistika tegemisel
Statistikaamet hindab ettevõtlusstatistikas peamiselt igasuguseid kogusummasid: ettevõtete kogukäivet, -tulu, -kasumit, töötajate koguarvu, keskmist palka, mediaanpalka jms. Nimetatud näitajate hindamiseks kasutatakse väiksemate ettevõtete osas tõenäosuslikku valikuuringut. Selleks, et hinnata Eesti keskmist palka mingil perioodil, tuleb kõigepealt hinnata kahte kogusummat: 1) kõigile palgatöötajatele väljamakstud brutopalka kokku ja 2) kõikide palgatöötajate koguarvu sellel perioodil. Perioodi keskmise brutopalga hinnang on kogubrutopalgana väljamakstud raha hinnang jagatud töötajate arvu hinnanguga. Ka kahe hinnangu suhtele saab arvutada standardvea, mille alusel iga statistikatarbija võib arvutada talle sobiva usaldusvahemiku. Keskmise brutopalga standardvea avaldab Statistikaamet koos keskmise palga endaga. 2016. aasta I kvartali keskmine kuupalk oli 1091 eurot standardveaga 8 eurot. Seega võib hinnata, et keskmise palga tegelik väärtus tänavu I kvartalis asub tõenäosusega 0,95 vahemikus 1091 – 2 x 8 = 1075 kuni 1091 + 2 x 8 = 1107 ja tõenäosusega 0,05 sellest vahemikust väljas.
Kummagi valimi võtmise viisi plussid ja miinused
Tõenäosusliku valikuuringu eelis on see, et on võimalik hinnata arvutatud statistika kvaliteeti ehk seda, kui lähedale oleme tõele jõudnud. Tõenäosusliku metoodika puudus on üldkogumi objektide nimekirja ehk freimi ehk registri olemasolu möödapääsmatus. Vähegi suuremate üldkogumite puhul on freimi loomine, ülalpidamine ja uuendamine kallis. Mis puutub empiirilistesse valimitesse, siis asjatundjad suudavad kokku panna väga häid valimeid ilma igasuguse nimekirjata, mistõttu empiirilised uuringud on oluliselt odavamad kui tõenäosuslikud ning nende kasutamine avaliku arvamus- ja turu-uuringutes igati õigustatud.